DeepXDE 科学机器学习库
本文最后更新于:16 小时前
DeepXDE 科学机器学习库
DeepXDE 由 Lu Lu 在布朗大学 George Karniadakis 教授的指导下于 2018 年夏季至 2020 年夏季开发,并得到 PhILM 的支持。 DeepXDE 最初是在布朗大学的 Subversion 中自行托管的,名称为 SciCoNet(科学计算神经网络)。 2019 年 2 月 7 日,SciCoNet 从 Subversion 迁移到 GitHub,更名为 DeepXDE。
DeepXDE 是一个用于科学机器学习的库。如果您需要一个深度学习库,请使用 DeepXDE ## DeepXDE 特性 DeepXDE 已经实现了如上所示的许多算法,并支持许多特性: * 复杂的域几何图形,没有专制网格生成。原始几何形状是间隔、三角形、矩形、多边形、圆盘、长方体和球体。其他几何可以使用三个布尔运算构建为构造实体几何 (CSG):并集、差集和交集。 * 多物理场,即(时间相关的)耦合偏微分方程。 * 5 种类型的边界条件 (BC):Dirichlet、Neumann、Robin、周期性和一般 BC,可以在任意域或点集上定义。 * 不同的神经网络,例如(堆叠/非堆叠)全连接神经网络、残差神经网络和(时空)多尺度傅里叶特征网络。 * 6种抽样方法:均匀抽样、伪随机抽样、拉丁超立方抽样、Halton序列、Hammersley序列、Sobol序列。 * 训练点可以在训练期间保持不变,也可以每隔一定的迭代重新采样一次。 * 方便保存 训练期间的模型,并加载训练好的模型。 * 使用 dropout 的不确定性量化。 * 许多不同的(加权)损失、优化器、学习率计划、指标等回调,用于在训练期间监控模型的内部状态和统计信息,例如提前停止。 * 使用户代码紧凑,与数学公式非常相似。 * DeepXDE 的所有组件都是松耦合的,因此 DeepXDE 结构良好且高度可配置。 * 可以轻松自定义 DeepXDE 以满足新的需求。
数值算例
问题设置
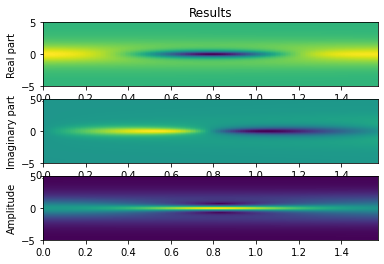
我们将求解由下式给出的非线性薛定谔方程 \[ i h_{t}+\frac{1}{2} h_{x x}+|h|^{2} h=0 \] 周期性边界条件为 \[ \begin{aligned} &x \in[-5,5], \quad t \in[0, \pi / 2] \\ &h(t,-5)=h(t, 5) \\ &h_{x}(t,-5)=h_{x}(t, 5) \end{aligned} \] 初始条件为 \[ h(0, x)=2 \operatorname{sech}(x) \] Deepxde 只使用实数,因此我们需要明确拆分复数 PDE 的实部和虚部。
代替单个残差 \[ f=i h_{t}+\frac{1}{2} h_{x x}+|h|^{2} h \] 我们得到两个(实值)残差 \[ \begin{aligned} &f_{\mathcal{R}}=u_{t}+\frac{1}{2} v_{x x}+\left(u^{2}+v^{2}\right) v \\ &f_{\mathcal{I}}=v_{t}-\frac{1}{2} u_{x x}-\left(u^{2}+v^{2}\right) u \end{aligned} \] 其中 \(u(x, t)\) 和 \(v(x, t)\) 分别表示 \(h\) 的实部和虚部。
1 | |
1 | |
1 | |
1 | |
1 | |
Adam 优化.
1 | |
Compiling model...
Building feed-forward neural network...
'build' took 0.076881 s
/usr/local/lib/python3.9/site-packages/deepxde/nn/tensorflow_compat_v1/fnn.py:103: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.
return tf.layers.dense(
/usr/local/lib/python3.9/site-packages/keras/legacy_tf_layers/core.py:261: UserWarning: `layer.apply` is deprecated and will be removed in a future version. Please use `layer.__call__` method instead.
return layer.apply(inputs)
2022-02-13 12:11:31.872944: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
'compile' took 0.775926 s
Initializing variables...
Training model...
Step Train loss Test loss Test metric
0 [7.09e-03, 4.63e-02, 2.41e+00, 1.27e-04, 2.85e-03, 2.84e-04, 1.15e+00, 9.62e-04] [7.09e-03, 4.63e-02, 2.41e+00, 1.27e-04, 2.85e-03, 2.84e-04, 1.15e+00, 9.62e-04] []
100 [9.38e-03, 1.96e-02, 1.04e-05, 2.25e-03, 1.65e-05, 1.21e-03, 1.06e-01, 1.02e-03] [9.38e-03, 1.96e-02, 1.04e-05, 2.25e-03, 1.65e-05, 1.21e-03, 1.06e-01, 1.02e-03] []
200 [1.57e-02, 1.78e-02, 1.47e-05, 9.31e-04, 6.18e-04, 1.61e-04, 4.71e-02, 1.02e-03] [1.57e-02, 1.78e-02, 1.47e-05, 9.31e-04, 6.18e-04, 1.61e-04, 4.71e-02, 1.02e-03] []
300 [1.62e-02, 1.43e-02, 7.50e-06, 7.65e-04, 5.41e-05, 4.26e-05, 3.74e-02, 1.32e-03] [1.62e-02, 1.43e-02, 7.50e-06, 7.65e-04, 5.41e-05, 4.26e-05, 3.74e-02, 1.32e-03] []
400 [1.60e-02, 1.39e-02, 5.21e-06, 8.29e-04, 1.79e-05, 3.45e-05, 3.28e-02, 1.64e-03] [1.60e-02, 1.39e-02, 5.21e-06, 8.29e-04, 1.79e-05, 3.45e-05, 3.28e-02, 1.64e-03] []
500 [1.54e-02, 1.39e-02, 3.18e-06, 7.63e-04, 1.47e-05, 4.23e-05, 2.94e-02, 1.88e-03] [1.54e-02, 1.39e-02, 3.18e-06, 7.63e-04, 1.47e-05, 4.23e-05, 2.94e-02, 1.88e-03] []
600 [1.51e-02, 1.38e-02, 2.07e-05, 6.36e-04, 2.54e-03, 4.45e-05, 2.73e-02, 2.29e-03] [1.51e-02, 1.38e-02, 2.07e-05, 6.36e-04, 2.54e-03, 4.45e-05, 2.73e-02, 2.29e-03] []
700 [1.44e-02, 1.37e-02, 4.71e-06, 5.26e-04, 2.15e-06, 2.84e-05, 2.59e-02, 1.82e-03] [1.44e-02, 1.37e-02, 4.71e-06, 5.26e-04, 2.15e-06, 2.84e-05, 2.59e-02, 1.82e-03] []
800 [1.37e-02, 1.35e-02, 5.04e-06, 4.37e-04, 3.51e-06, 1.36e-05, 2.47e-02, 1.66e-03] [1.37e-02, 1.35e-02, 5.04e-06, 4.37e-04, 3.51e-06, 1.36e-05, 2.47e-02, 1.66e-03] []
900 [1.31e-02, 1.34e-02, 4.33e-06, 3.77e-04, 7.51e-06, 5.86e-06, 2.35e-02, 1.49e-03] [1.31e-02, 1.34e-02, 4.33e-06, 3.77e-04, 7.51e-06, 5.86e-06, 2.35e-02, 1.49e-03] []
1000 [1.25e-02, 1.32e-02, 2.72e-06, 3.28e-04, 5.27e-06, 4.65e-06, 2.24e-02, 1.31e-03] [1.25e-02, 1.32e-02, 2.72e-06, 3.28e-04, 5.27e-06, 4.65e-06, 2.24e-02, 1.31e-03] []
Best model at step 1000:
train loss: 4.97e-02
test loss: 4.97e-02
test metric: []
'train' took 188.992807 s
(<deepxde.model.LossHistory at 0x13422ad90>,
<deepxde.model.TrainState at 0x10d759850>)L-BFGS 优化.
1 | |
Compiling model...
'compile' took 0.554160 s
Training model...
Step Train loss Test loss Test metric
1000 [1.25e-02, 1.32e-02, 2.72e-06, 3.28e-04, 5.27e-06, 4.65e-06, 2.24e-02, 1.31e-03] [1.25e-02, 1.32e-02, 2.72e-06, 3.28e-04, 5.27e-06, 4.65e-06, 2.24e-02, 1.31e-03] []
2000 [7.03e-04, 7.62e-04, 6.76e-06, 1.33e-05, 2.88e-07, 8.49e-06, 4.01e-04, 3.86e-05]
INFO:tensorflow:Optimization terminated with:
Message: STOP: TOTAL NO. of f AND g EVALUATIONS EXCEEDS LIMIT
Objective function value: 0.001928
Number of iterations: 945
Number of functions evaluations: 1001
2001 [7.18e-04, 7.43e-04, 6.27e-06, 1.23e-05, 2.94e-07, 8.89e-06, 4.01e-04, 3.82e-05] [7.18e-04, 7.43e-04, 6.27e-06, 1.23e-05, 2.94e-07, 8.89e-06, 4.01e-04, 3.82e-05] []
Best model at step 2001:
train loss: 1.93e-03
test loss: 1.93e-03
test metric: []
'train' took 179.449384 s
(<deepxde.model.LossHistory at 0x13422ad90>,
<deepxde.model.TrainState at 0x10d759850>)1 | |
课程视频及参考文献
课程视频下载密码:safh
Physics Informed Deep Learning (Part I)
Physics Informed Deep Learning (Part II)
DeepXDE- A Deep Learning Library for Solving Differential Equations
文献解读-Physics Informed Deep Learning(PINN)
课程介绍及视频资源来自国家天元数学东南中心官网,若有侵权,请联系作者删除
作者邮箱:turingscat@126.com
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!